
8-900-374-94-44

Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида — Соломона, работающие с байтами (октетами).
Код Рида — Соломона является частным случаем БЧХ-кода.
В настоящее время широко используется в системах восстановления данных с компакт-дисков, при создании архивов с информацией для восстановления в случае повреждений, в помехоустойчивом кодировании.
Содержание
|
Код Рида — Соломона был изобретён в 1960 году сотрудниками лаборатории Линкольна Массачуссетского технологического института Ирвином Ридом (англ.) и Густавом Соломоном (англ.). Идея использования этого кода была представлена в статье «Polynomial Codes over Certain Finite Fields». Первое применение код Рида — Соломона получил в 1982 году в серийном выпуске компакт-дисков. Эффективный алгоритм декодирования был предложен в 1969 году Элвином Берлекэмпом (англ.) и Джэймсом Месси (алгоритм Берлекэмпа — Мэсси).
Коды Рида — Соломона являются важным частным случаем БЧХ-кода, корни порождающего полинома которого лежат в том же поле, над каким и строится код (m = 1). Пусть α — элемент поля порядка . Если α — примитивный элемент, то его порядок равен q − 1, то есть . Тогда нормированный полином g(x) минимальной степени над полем , корнями которого являются d − 1 подряд идущих степеней элемента α, является порождающим полиномом кода Рида — Соломона над полем :
Пусть α — элемент поля порядка . Если α — примитивный элемент, то его порядок равен q − 1, то есть . Тогда нормированный полином g(x) минимальной степени над полем , корнями которого являются d − 1 подряд идущих степеней элемента α, является порождающим полиномом кода Рида — Соломона над полем :
где l0 — некоторое целое число (в том числе 0 и 1), с помощью которого иногда удается упростить кодер. Обычно полагается l0 = 1. Степень многочлена равна d − 1.
Длина полученного кода n, минимальное расстояние d (минимальное расстояние d линейного кода является минимальным из всех расстояний Хемминга всех пар кодовых слов, см. Линейный код). Код содержит r = d − 1 = deg(g(x)) проверочных символов, где deg() обозначает степень полинома; число информационных символов k = n − r = n − d + 1. Таким образом и код Рида — Соломона является разделимым кодом с максимальным расстоянием (является оптимальным в смысле границы Синглтона).
Кодовый полином c(x) может быть получен из информационного полинома m(x), , путем перемножения m(x) и g(x):
c(x) = m(x)g(x)
Код Рида — Соломона над , исправляющий t ошибок, требует 2t проверочных символов и с его помощью исправляются произвольные пакеты ошибок длиной t и меньше. Согласно теореме о границе Рейгера, коды Рида — Соломона являются оптимальными с точки зрения соотношения длины пакета и возможности исправления ошибок — используя 2t дополнительных проверочных символов исправляются t ошибок (и менее).
Теорема (граница Рейгера). Каждый линейный блоковый код, исправляющий все пакеты длиной t и менее, должен содержать, по меньшей мере, 2t проверочных символов.
Код Рида — Соломона является одним из наиболее мощных кодов, исправляющих многократные пакеты ошибок. Применяется в каналах, где пакеты ошибок могут образовываться столь часто, что их уже нельзя исправлять с помощью кодов, исправляющих одиночные ошибки.
Применяется в каналах, где пакеты ошибок могут образовываться столь часто, что их уже нельзя исправлять с помощью кодов, исправляющих одиночные ошибки.
(qm − 1,qm − 1 − 2t)-код Рида — Соломона над полем с кодовым расстоянием d = 2t + 1 можно рассматривать как ((qm − 1)m,(qm − 1 − 2t)m)-код над полем , который может исправлять любую комбинацию ошибок, сосредоточенную в t или меньшем числе блоков из m символов. Наибольшее число блоков длины m, которые может затронуть пакет длины li, где , не превосходит ti, поэтому код, который может исправить t блоков ошибок, всегда может исправить и любую комбинацию из p пакетов общей длины l, если .
Кодирование с помощью кода Рида — Соломона может быть реализовано двумя способами: систематическим и несистематическим (см. [1], описание кодировщика).
[1], описание кодировщика).
При несистематическом кодировании информационное слово умножается на некий неприводимый полином в поле Галуа. Полученное закодированное слово полностью отличается от исходного и для извлечения информационного слова нужно выполнить операцию декодирования и уже потом можно проверить данные на содержание ошибок. Такое кодирование требует большие затраты ресурсов только на извлечение информационных данных, при этом они могут быть без ошибок.
Структура систематического кодового слова Рида — Соломона
При систематическом кодировании к информационному блоку из k символов приписываются 2t проверочных символов, при вычислении каждого проверочного символа используются все k символов исходного блока. В этом случае нет затрат ресурсов при извлечении исходного блока, если информационное слово не содержит ошибок, но кодировщик/декодировщик должен выполнить k(n − k) операций сложения и умножения для генерации проверочных символов. Кроме того, так как все операции проводятся в поле Галуа, то сами операции кодирования/декодирования требуют много ресурсов и времени. Быстрый алгоритм декодирования, основанный на быстром преобразовании Фурье, выполняется за время порядка
Кроме того, так как все операции проводятся в поле Галуа, то сами операции кодирования/декодирования требуют много ресурсов и времени. Быстрый алгоритм декодирования, основанный на быстром преобразовании Фурье, выполняется за время порядка
При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного слова S длины k на неприводимый полином при систематическом кодировании можно выполнить следующим образом:
Кодировщик строится из сдвиговых регистров, сумматоров и умножителей. Сдвиговый регистр состоит из ячеек памяти, в каждой из которых находится один элемент поля Галуа.
Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия:
Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое слово на порождающий многочлен. Если при делении возникает остаток, то в слове есть ошибка. Остаток от деления является синдромом ошибки.
Вычисленный синдром ошибки не указывает на положение ошибок. Степень полинома синдрома равна 2t, что много меньше степени кодового слова n. Для получения соответствия между ошибкой и ее положением в сообщении строится полином ошибок. Полином ошибок реализуется с помощью алгоритма Берлекэмпа — Месси, либо с помощью алгоритма Евклида. Алгоритм Евклида имеет простую реализацию, но требует больших затрат ресурсов. Поэтому чаще применяется более сложный, но менее затратоемкий алгоритм Берлекэмпа — Месси. Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове.
Поэтому чаще применяется более сложный, но менее затратоемкий алгоритм Берлекэмпа — Месси. Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове.
На этом этапе ищутся корни полинома ошибки, определяющие положение искаженных символов в кодовом слове. Реализуется с помощью процедуры Ченя, равносильной полному перебору. В полином ошибок последовательно подставляются все возможные значения, когда полином обращается в ноль — корни найдены.
Основная статья: Код Боуза — Чоудхури — Хоквингема#Методы декодирования
По синдрому ошибки и найденным корням полинома с помощью алгоритма Форни определяется характер ошибки и строится маска искаженных символов. Эта маска накладывается на кодовое слово с помощью операции XOR и искаженные символы восстанавливаются. После этого отбрасываются проверочные символы и получается восстановленное информационное слово.
В настоящий момент коды Рида — Соломона имеют очень широкую область применения благодаря их способности находить и исправлять многократные пакеты ошибок.
Код Рида — Соломона используется при записи и чтении в контроллерах оперативной памяти, при архивировании данных, записи информации на жесткие диски (ECC), записи на CD/DVD диски. Даже если поврежден значительный объем информации, испорчено несколько секторов дискового носителя, то коды Рида — Соломона позволяют восстановить большую часть потерянной информации. Также используется при записи на такие носители, как магнитные ленты и штрихкоды.
Возможные ошибки при чтении с диска появляются уже на этапе производства диска, так как сделать идеальный диск при современных технологиях невозможно. Так же ошибки могут быть вызваны царапинами на поверхности диска, пылью и т. д. Поэтому при изготовлении читаемого компакт-диска используется система коррекции CIRC (Cross Interleaved Reed Solomon Code). Эта коррекция реализована во всех устройствах, позволяющих считывать данные с CD дисков, в виде чипа с прошивкой firmware. Нахождение и коррекция ошибок основана на избыточности и перемежении (redundancy & interleaving). Избыточность примерно 25 % от исходной информации.
Эта коррекция реализована во всех устройствах, позволяющих считывать данные с CD дисков, в виде чипа с прошивкой firmware. Нахождение и коррекция ошибок основана на избыточности и перемежении (redundancy & interleaving). Избыточность примерно 25 % от исходной информации.
При записи на цифровые аудиокомпакт-диски (Compact Disc Digital Audio — CD-DA) используется стандарт Red Book. Коррекция ошибок происходит на двух уровнях C1 и C2. При кодировании на первом этапе происходит добавление проверочных символов к исходным данным, на втором этапе информация снова кодируется. Кроме кодирования осуществляется также перемешивание (перемежение) байтов, чтобы при коррекции блоки ошибок распались на отдельные биты, которые легче исправляются. На первом уровне обнаруживаются и исправляются ошибочные блоки длиной один и два байта (один и два ошибочных символа соответственно). Ошибочные блоки длиной три байта обнаруживаются и передаются на следующий уровень. На втором уровне обнаруживаются и исправляются ошибочные блоки, возникшие в C2, длиной 1 и 2 байта. Обнаружение трех ошибочных символов является фатальной ошибкой и не может быть исправлено.
Обнаружение трех ошибочных символов является фатальной ошибкой и не может быть исправлено.
Этот алгоритм кодирования используется при передаче данных по сетям WiMAX, в оптических линиях связи, в спутниковой и радиорелейной связи. Метод прямой коррекции ошибок в проходящем трафике (Forward Error Correction, FEC) основывается на кодах Рида — Соломона.
Пусть t = 2,l0 = 1. Тогда
g(x) = (x − α)(x − α2)(x − α3
.
Степень g(x) равна 4, n − k = 4 и k = 11. Каждому элементу поля GF(16) можно сопоставить 4 бита. Информационный многочлен является последовательностью 11 символов из GF(16), что эквивалентно 44 битам, а все кодовое слово является набором из 60 бит.
Пусть t = 2,l0 = 4. Тогда
g(x) = (x − α4)(x − α5)(x − α6)(x − α0) = x4 + α6x3 + α6x2 + α3x + α
.
Пусть информационный многочлен имеет вид
m(x) = α4x2 + x + α3
.
Кодовое слово несистематического кода запишется в виде
c(x) = m(x)g(x) = (α4x2 + x + α3)(x4 + α6x3 + α6x2 + α3x + α) = α4x6 + αx5 + α6x4 + 0x3 + 0x2 + α5x + α4
что представляет собой последовательность семи восьмеричных символов.
ОглавлениеОТ РЕДАКТОРА ПЕРЕВОДАПРЕДИСЛОВИЕ ГЛАВА 1. ВВЕДЕНИЕ 1.1. ДИСКРЕТНЫЙ КАНАЛ, СВЯЗИ 1.2. ИСТОРИЯ КОДИРОВАНИЯ, КОНТРОЛИРУЮЩЕГО ОШИБКИ 1.  3. ПРИЛОЖЕНИЯ 3. ПРИЛОЖЕНИЯ1.4. ОСНОВНЫЕ ПОНЯТИЯ 1.5. ПРОСТЕЙШИЕ КОДЫ ГЛАВА 2. ВВЕДЕНИЕ В АЛГЕБРУ 2.1. 2-ПОЛЕ И 6-10-ПОЛЕ 2.2. ГРУППЫ 2.3. КОЛЬЦА 2.4. ПОЛЯ 2.5. ВЕКТОРНЫЕ ПРОСТРАНСТВА 2.6. ЛИНЕЙНАЯ АЛГЕБРА ГЛАВА 3. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 3.1. СТРУКТУРА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ 3.2. МАТРИЧНОЕ ОПИСАНИЕ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ 3.3. СТАНДАРТНОЕ РАСПОЛОЖЕНИЕ 3.4. КОДЫ ХЭММИНГА 3.5. СОВЕРШЕННЫЕ И КВАЗИСОВЕРШЕННЫЕ КОДЫ 3.6. ПРОСТЫЕ ПРЕОБРАЗОВАНИЯ ЛИНЕЙНОГО КОДА 3.7. КОДЫ РИДА—МАЛЛЕРА ГЛАВА 4. АРИФМЕТИКА ПОЛЕЙ ГАЛУА 4.2. КОНЕЧНЫЕ ПОЛЯ, ОСНОВАННЫЕ НА КОЛЬЦЕ ЦЕЛЫХ ЧИСЕЛ 4.3. КОЛЬЦА МНОГОЧЛЕНОВ 4.4. КОНЕЧНЫЕ ПОЛЯ, ОСНОВАННЫЕ НА КОЛЬЦАХ МНОГОЧЛЕНОВ 4.5. ПРИМИТИВНЫЕ ЭЛЕМЕНТЫ 4.6. СТРУКТУРА КОНЕЧНОГО ПОЛЯ ГЛАВА 5. ЦИКЛИЧЕСКИЕ КОДЫ 5.2. ПОЛИНОМИАЛЬНОЕ ОПИСАНИЕ ЦИКЛИЧЕСКИХ КОДОВ 5.3. МИНИМАЛЬНЫЕ МНОГОЧЛЕНЫ И СОПРЯЖЕНИЯ 5.4. МАТРИЧНОЕ ОПИСАНИЕ ЦИКЛИЧЕСКИХ КОДОВ 5.5. КОДЫ ХЭММИНГА КАК ЦИКЛИЧЕСКИЕ КОДЫ 5.  6. ЦИКЛИЧЕСКИЕ КОДЫ, ИСПРАВЛЯЮЩИЕ ДВЕ ОШИБКИ 6. ЦИКЛИЧЕСКИЕ КОДЫ, ИСПРАВЛЯЮЩИЕ ДВЕ ОШИБКИ5.7. ЦИКЛИЧЕСКИЕ КОДЫ, ИСПРАВЛЯЮЩИЕ ПАКЕТЫ ОШИБОК 5.8. ДВОИЧНЫЙ КОД ГОЛЕЯ 5.9. КВАДРАТИЧНО-ВЫЧЕТНЫЕ КОДЫ ГЛАВА 6. СХЕМНАЯ РЕАЛИЗАЦИЯ ЦИКЛИЧЕСКОГО КОДИРОВАНИЯ 6.1. ЛОГИЧЕСКИЕ ЦЕПИ ДЛЯ АРИФМЕТИКИ КОНЕЧНОГО ПОЛЯ 6.2. ЦИФРОВЫЕ ФИЛЬТРЫ 6.3. КОДЕРЫ И ДЕКОДЕРЫ НА РЕГИСТРАХ СДВИГА 6.4. ДЕКОДЕР МЕГГИТТА 6.5. ВЫЛАВЛИВАНИЕ ОШИБОК 6.6. УКОРОЧЕННЫЕ ЦИКЛИЧЕСКИЕ КОДЫ 6.7. ДЕКОДЕР МЕГГИТТА ДЛЯ. КОДА ГОЛЕЯ ГЛАВА 7. КОДЫ БОУЗА-ЧОУДХУРИ-ХОКВИНГЕМА 7.2. ДЕКОДЕР ПИТЕРСОНА ГОРЕНСТЕЙНА—ЦИРЛЕРА 7.3. КОДЫ РИДА СОЛОМОНА 7.5. БЫСТРОЕ ДЕКОДИРОВАНИЕ КОДОВ БЧХ 7.6. ДЕКОДИРОВАНИЕ ДВОИЧНЫХ КОДОВ БЧХ 7.7. ДЕКОДИРОВАНИЕ С ПОМОЩЬЮ АЛГОРИТМА ЕВКЛИДА 7.8. КАСКАДНЫЕ (ГНЕЗДОВЫЕ) КОДЫ 7.9. КОДЫ ЮСТЕСЕНА ГЛАВА 8. КОДЫ, ОСНОВАННЫЕ НА СПЕКТРАЛЬНЫХ МЕТОДАХ 8.2. ОГРАНИЧЕНИЯ СОПРЯЖЕННОСТИ И ИДЕМПОТЕНТЫ 8.3. СПЕКТРАЛЬНОЕ ОПИСАНИЕ ЦИКЛИЧЕСКИХ КОДОВ 8.4. РАСШИРЕННЫЕ КОДЫ РИДА-СОЛОМОНА 8.  5. РАСШИРЕННЫЕ КОДЫ БЧХ 5. РАСШИРЕННЫЕ КОДЫ БЧХ8.6. АЛЬТЕРНАНТНЫЕ КОДЫ 8.7. ХАРАКТЕРИСТИКИ АЛЬТЕРНАНТНЫХ КОДОВ 8.8. КОДЫ ГОППЫ 8.9. КОДЫ ПРЕПАРАТЫ ГЛАВА 9. АЛГОРИТМЫ, ОСНОВАННЫЕ НА СПЕКТРАЛЬНЫХ МЕТОДАХ 9.2. ИСПРАВЛЕНИЕ СТИРАНИЙ И ОШИБОК 9.3. ДЕКОДИРОВАНИЕ РАСШИРЕННЫХ КОДОВ РИДА—СОЛОМОНА 9.4. ДЕКОДИРОВАНИЕ РАСШИРЕННЫХ КОДОВ БЧХ 9.5. ДЕКОДИРОВАНИЕ ВО ВРЕМЕННОЙ ОБЛАСТИ 9.6. ДЕКОДИРОВАНИЕ ЗА ГРАНИЦЕЙ БЧХ 9.7. ДЕКОДИРОВАНИЕ АЛЬТЕРНАНТНЫХ КОДОВ 9.8. ВЫЧИСЛЕНИЕ ПРЕОБРАЗОВАНИЙ В КОНЕЧНЫХ ПОЛЯХ ГЛАВА 10. МНОГОМЕРНЫЕ СПЕКТРАЛЬНЫЕ МЕТОДЫ 10.1. КОДЫ-ПРОИЗВЕДЕНИЯ 10.2. КИТАЙСКИЕ ТЕОРЕМЫ ОБ ОСТАТКАХ 10.3. ДЕКОДИРОВАНИЕ КОДА-ПРОИЗВЕДЕНИЯ 10.4. МНОГОМЕРНЫЕ СПЕКТРЫ 10.5. БЫСТРЫЕ КОДЫ БЧХ 10.6. ДЕКОДИРОВАНИЕ МНОГОМЕРНЫХ КОДОВ 10.7. ДЛИННЫЕ КОДЫ НАД МАЛЫМИ ПОЛЯМИ ГЛАВА 11. БЫСТРЫЕ АЛГОРИТМЫ 11.1. ЛИНЕЙНАЯ СВЕРТКА И ЦИКЛИЧЕСКАЯ СВЕРТКА 11.2. БЫСТРЫЕ АЛГОРИТМЫ СВЕРТКИ 11.3. БЫСТРЫЕ ПРЕОБРАЗОВАНИЯ ФУРЬЕ 11.4. АЛГОРИТМЫ АГАРВАЛА—КУЛИ ВЫЧИСЛЕНИЯ СВЕРТОК 11.  5. АЛГОРИТМ ВИНОГРАДА БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ 5. АЛГОРИТМ ВИНОГРАДА БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ11.6. УСКОРЕННЫЙ АЛГОРИТМ БЕРЛЕКЭМПА—МЕССИ 11.7. РЕКУРРЕНТНЫЙ АЛГОРИТМ БЕРЛЕКЭМПА—МЕССИ 11.8. УСКОРЕННОЕ ДЕКОДИРОВАНИЕ КОДОВ БЧХ 11.9. СВЕРТКА В СУРРОГАТНЫХ ПОЛЯХ ГЛАВА 12. СВЕРТОЧНЫЕ КОДЫ 12.2. ОПИСАНИЕ СВЕРТОЧНЫХ КОДОВ С ПОМОЩЬЮ МНОГОЧЛЕНОВ 12.3. ИСПРАВЛЕНИЕ ОШИБОК И ПОНЯТИЯ РАССТОЯНИЯ 12.4. МАТРИЧНОЕ ОПИСАНИЕ СВЕРТОЧНЫХ КОДОВ 12.5. НЕКОТОРЫЕ ПРОСТЫЕ СВЕРТОЧНЫЕ КОДЫ 12.6. АЛГОРИТМЫ СИНДРОМНОГО ДЕКОДИРОВАНИЯ 12.7. ОБЕРТОЧНЫЕ КОДЫ ДЛЯ ИСПРАВЛЕНИЯ ПАКЕТОВ ОШИБОК 12.8. АЛГОРИТМ ДЕКОДИРОВАНИЯ ВИТЕРБИ 12.9. АЛГОРИТМЫ ПОИСКА ПО РЕШЕТКЕ ГЛАВА 13. КОДЫ И АЛГОРИТМЫ ДЛЯ ДЕКОДИРОВАНИЯ МАЖОРИТАРНЫМ МЕТОДОМ 13.1. ДЕКОДИРОВАНИЕ МАЖОРИТАРНЫМ МЕТОДОМ 13.2. СХЕМЫ МАЖОРИТАРНОГО ДЕКОДИРОВАНИЯ 13.3. АФФИННЫЕ ПЕРЕСТАНОВКИ ДЛЯ ЦИКЛИЧЕСКИХ КОДОВ 13.4. ЦИКЛИЧЕСКИЕ КОДЫ, ОСНОВАННЫЕ НА ПЕРЕСТАНОВКАХ 13.5. СВЕРТОЧНЫЕ КОДЫ С МАЖОРИТАРНЫМ ДЕКОДИРОВАНИЕМ 13.6. ОБОБЩЕННЫЕ КОДЫ РИДА—МАЛЛЕРА 13.  7. ЕВКЛИДОВО-ГЕОМЕТРИЧЕСКИЕ КОДЫ 7. ЕВКЛИДОВО-ГЕОМЕТРИЧЕСКИЕ КОДЫ13.8. ПРОЕКТИВНО-ГЕОМЕТРИЧЕСКИЕ КОДЫ ГЛАВА 14. КОМПОЗИЦИЯ И ХАРАКТЕРИСТИКИ КОНТРОЛИРУЮЩИХ ОШИБКИ КОДОВ 14.2. ВЕРОЯТНОСТИ ОШИБОЧНОГО ДЕКОДИРОВАНИЯ И НЕУДАЧНОГО ДЕКОДИРОВАНИЯ 14.3. РАСПРЕДЕЛЕНИЕ ВЕСОВ СВЕРТОЧНЫХ КОДОВ 14.4. ГРАНИЦЫ МИНИМАЛЬНОГО РАССТОЯНИЯ ДЛЯ БЛОКОВЫХ КОДОВ 14.5. ГРАНИЦЫ МИНИМАЛЬНОГО РАССТОЯНИЯ ДЛЯ СВЕРТОЧНЫХ КОДОВ ГЛАВА 15. ЭФФЕКТИВНАЯ ПЕРЕДАЧА СИГНАЛОВ ПО ЗАШУМЛЕННЫМ КАНАЛАМ 15.1. ОГРАНИЧЕННЫЙ ПО ПОЛОСЕ ГАУССОВСКИЙ КАНАЛ 15.2. ЭНЕРГИЯ НА БИТ И ЧАСТОТА ОШИБОК НА БИТ 15.3. МЯГКОЕ ДЕКОДИРОВАНИЕ БЛОКОВЫХ КОДОВ 15.4. МЯГКОЕ ДЕКОДИРОВАНИЕ СВЕРТОЧНЫХ КОДОВ 15.5. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕ ЛИТЕРАТУРА |
Коды Рида-Соломона
Введение в коды Рида-Соломона: принципы, архитектура и реализация
1. Введение
Коды Рида-Соломона представляют собой блочные коды с исправлением ошибок с широким
диапазон приложений в цифровой связи и хранения.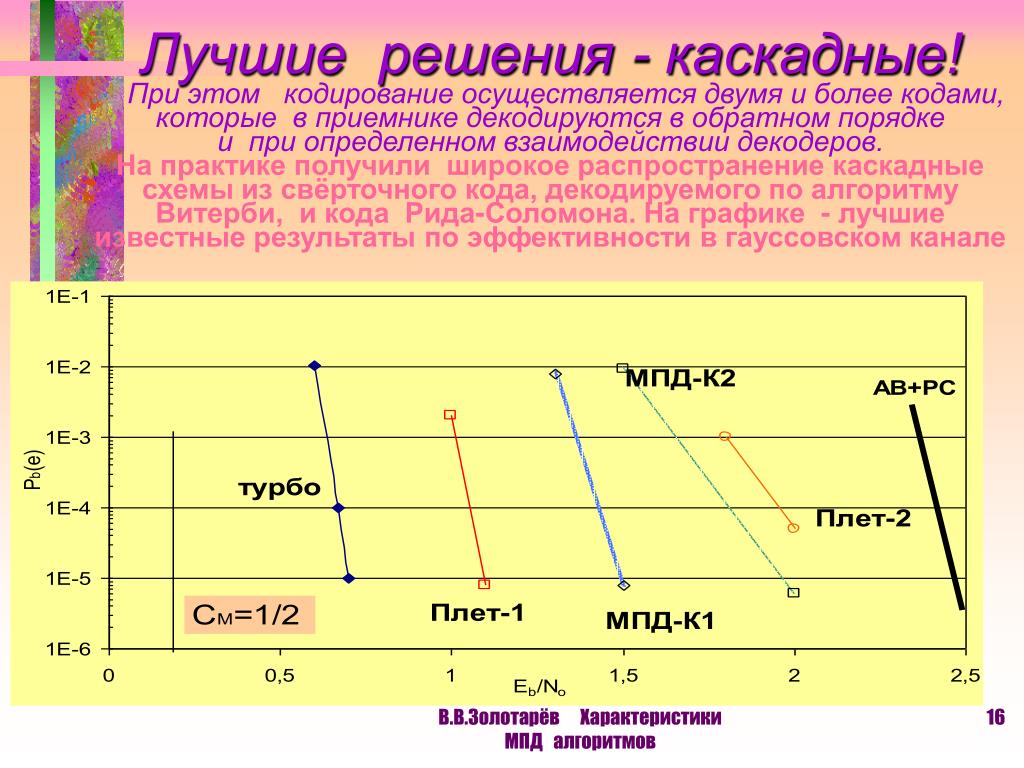 Рид-Соломон
коды используются для исправления ошибок во многих системах, включая:
Рид-Соломон
коды используются для исправления ошибок во многих системах, включая:
Здесь показана типичная система:
Кодер Рида-Соломона берет блок цифровых данных и добавляет «лишние» биты. Ошибки возникают при передаче или хранении по ряду причин (например, шум или помехи, царапины на компакт-диск и др.). Декодер Рида-Соломона обрабатывает каждый блок и пытается для исправления ошибок и восстановления исходных данных. Количество и тип ошибки, которые можно исправить, зависит от характеристик системы Рида-Соломона. код.
2. Свойства кодов Рида-Соломона
Коды Рида-Соломона являются подмножеством кодов БЧХ и представляют собой линейные блочные коды.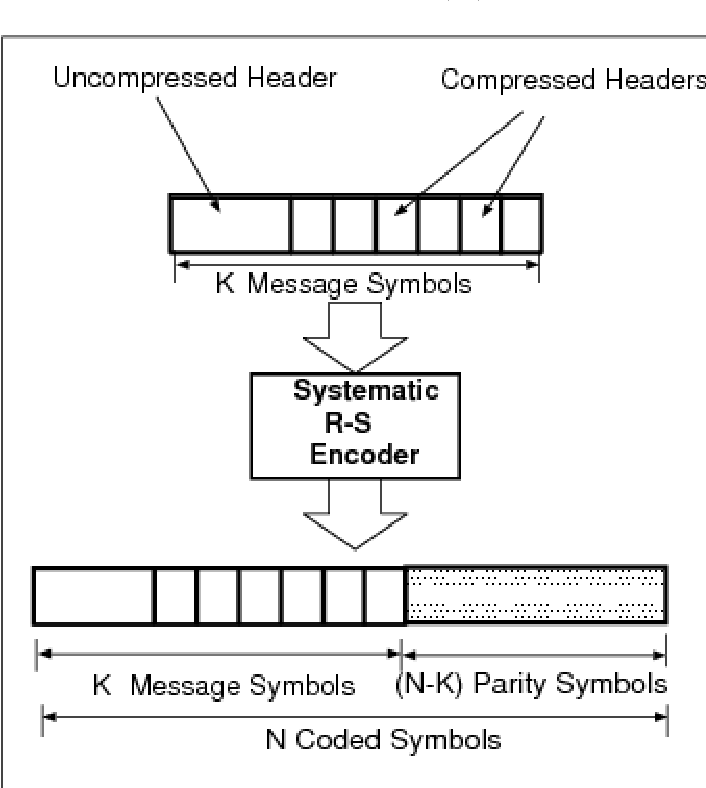 Код Рида-Соломона определяется как RS( n,k ) с s -битными символами.
Код Рида-Соломона определяется как RS( n,k ) с s -битными символами.
Это означает, что кодировщик принимает к символов данных из с битов каждый и добавляет символы четности, чтобы получить кодовое слово из n символов. Имеется n-k символов четности по s бит каждый. Декодер Рида-Соломона можно исправить до t символов, содержащих ошибки в кодовом слове, где 2t = н-к .
На следующей диаграмме показано типичное кодовое слово Рида-Соломона (это известный как систематический код, потому что данные остаются неизменными, а четность добавляются символы):
Пример: Популярным кодом Рида-Соломона является RS(255,223) с 8-битным символы. Каждое кодовое слово содержит 255 байтов кодового слова, из которых 223 байта являются данными, а 32 байта — четностью. Для этого кода:
n = 255, k = 223, s = 8
2t = 32, t = 16
Декодер может исправить любые 16 ошибок символов в кодовом слове: т.
е. ошибки размером до 16 байтов в любом месте кодового слова могут быть автоматически исправленный.
При заданном размере символа s максимальная длина кодового слова (n) для алгоритма Рида-Соломона код n = 2 с 1
Например, максимальная длина кода с 8-битными символами (s=8) составляет 255 байт.
Коды Рида-Соломона могут быть сокращены (концептуально) путем создания числа нулевых символов данных в кодере, не передавая их, а затем повторно вставляя их в декодере.
Пример : Описанный выше код (255,223) можно сократить. до (200 168). Кодер принимает блок из 168 байтов данных (концептуально). добавляет 55 нулевых байтов, создает кодовое слово (255 223) и передает только 168 байт данных и 32 байта четности.
Количество вычислительной «мощности», необходимой для кодирования и декодирования
Коды Рида-Соломона связаны с количеством символов четности на кодовое слово. Большое значение t означает, что можно исправить большое количество ошибок.
но требует большей вычислительной мощности, чем небольшое значение t.
Большое значение t означает, что можно исправить большое количество ошибок.
но требует большей вычислительной мощности, чем небольшое значение t.
Ошибки символов
Ошибка одного символа возникает, когда неверный 1 бит в символе или когда все биты в символе неверны.
Коды Рида-СоломонаПример : RS(255,223) может исправить 16 ошибок символов. В худшем случае могут возникнуть 16-битные ошибки, каждая в отдельном символе (байте), так что декодер исправляет 16-битные ошибки. В лучшем случае 16 полных байт ошибки возникают так, что декодер исправляет 16 x 8 битовых ошибок.
особенно хорошо подходят для коррекции ошибки (где серия битов в кодовом слове получена с ошибкой).
Расшифровка
Процедуры алгебраического декодирования Рида-Соломона могут исправлять ошибки и стирания.
Стирание происходит, когда известно положение ошибочного символа. Декодер
может исправить до t ошибок или до 2t стираний. Стирание
информация часто может быть предоставлена демодулятором в цифровой связи
системы, т.е. демодулятор «помечает» принятые символы, которые
вероятно, содержит ошибки.
Декодер
может исправить до t ошибок или до 2t стираний. Стирание
информация часто может быть предоставлена демодулятором в цифровой связи
системы, т.е. демодулятор «помечает» принятые символы, которые
вероятно, содержит ошибки.
При декодировании кодового слова возможны три исхода:
1. Если 2s + r < 2t (s ошибок, r стираний), то переданный оригинал кодовое слово всегда будет восстанавливаться,
ИНАЧЕ
2. Декодер обнаружит, что не может восстановить исходный код слово и указать на этот факт.
ИЛИ
3. Декодер неправильно декодирует и восстанавливает неверное кодовое слово без любое указание.
Вероятность каждой из трех возможностей зависит от конкретного Код Рида-Соломона и по количеству и распределению ошибок.
Усиление кодирования
Преимущество использования кодов Рида-Соломона заключается в том, что вероятность
ошибка, остающаяся в декодированных данных (обычно) намного меньше, чем
вероятность ошибки, если Рид-Соломон не используется. Это часто описывается
как усиление кодирования .
Это часто описывается
как усиление кодирования .
Пример: Система цифровой связи предназначена для работы при коэффициенте битовых ошибок (BER) 10 -9 , т. е. не более 1 из 10 9 биты принимаются ошибочно. Этого можно добиться, увеличив мощность передатчика или , добавив Reed-Solomon (или другой тип Прямое исправление ошибок). Рид-Соломон позволяет системе добиться этого целевой BER с более низкой выходной мощностью передатчика. Энергосбережение данное Ридом-Соломоном (в децибелах) равно коэффициент усиления кодирования .
3. Архитектуры кодирования и декодирования кодов Рида-Соломона
Кодирование и декодирование Рида-Соломона может выполняться программно или в аппаратуре специального назначения.
Арифметика конечного поля (Галуа)
Коды Рида-Соломона основаны на специальной области математики, известной
как поля Галуа или конечные поля. Конечное поле обладает тем свойством, что
арифметические операции (+,-,x и т.д.) над элементами поля всегда имеют результат
в поле. Кодер или декодер Рида-Соломона должен выполнять эти
арифметические операции. Эти операции требуют специального оборудования или программного обеспечения.
функции для реализации.
Конечное поле обладает тем свойством, что
арифметические операции (+,-,x и т.д.) над элементами поля всегда имеют результат
в поле. Кодер или декодер Рида-Соломона должен выполнять эти
арифметические операции. Эти операции требуют специального оборудования или программного обеспечения.
функции для реализации.
Полином генератора
Кодовое слово Рида-Соломона генерируется с использованием специального полинома. Все действительные кодовые слова точно делятся на полином генератора. общая форма полинома генератора:
и кодовое слово построено с использованием:
с(х) = г(х).i(х)
, где g(x) — образующий полином, i(x) — информационный блок, c(x) является допустимым кодовым словом, а a упоминается как примитивный элемент поле.
Пример: Генератор для RS(255,249)
3. 1 Архитектура энкодера
1 Архитектура энкодера
2t символов четности в систематическом кодовом слове Рида-Соломона предоставлено:
На следующей диаграмме показана архитектура систематического RS(255,249) кодировщик:
Каждый из 6 регистров содержит символ (8 бит). Арифметические операторы выполнять сложение или умножение конечного поля на полном символе.
3.2 Архитектура декодера
Общая архитектура для декодирования кодов Рида-Соломона показана на следующую схему.
Ключ
| р(х) | Получено кодовое слово |
| Si | Синдромы |
| Л(х) | Полином локатора ошибок |
| Си | Места ошибок |
| Йи | Значения ошибок |
| с(х) | Восстановлено кодовое слово |
| против | Количество ошибок |
Полученное кодовое слово r(x) является исходным (переданным) кодовым словом c(x) плюс ошибки:
г(х) = с(х) + е(х)
Декодер Рида-Соломона пытается определить положение и величину
до t ошибок (или 2t стираний) и исправлять ошибки или стирания.
Расчет синдрома
Этот расчет аналогичен расчету четности. Рид-Соломон кодовое слово имеет 2t синдромов , которые зависят только от ошибок (не от передаваемое кодовое слово). Синдромы можно рассчитать, заменив 2t корней образующего многочлена g(x) в r(x).
Поиск мест ошибок символов
Это включает решение одновременных уравнений с t неизвестными. Несколько для этого доступны быстрые алгоритмы. Эти алгоритмы используют преимущества специальной матричной структуры кодов Рида-Соломона и значительно сократить требуемые вычислительные усилия. В общем случае задействованы два шага:
Найти полином локатора ошибок
Это можно сделать с помощью алгоритма Берлекампа-Месси или алгоритма Евклида. Алгоритм Евклида, как правило, более широко используется на практике, потому что он легче реализовать: однако алгоритм Берлекампа-Месси имеет тенденцию привести к более эффективной аппаратной и программной реализации.
Найдите корни этого многочлена
Это делается с помощью алгоритма поиска Chien.
Поиск значений ошибок символов
Опять же, это включает решение одновременных уравнений с t неизвестными. Широко используемый быстрый алгоритм — алгоритм Форни.
4. Внедрение кодеров и декодеров Рида-Соломона
Аппаратная реализация
Существует ряд коммерческих аппаратных реализаций. Многие существующие
системы используют готовые интегральные схемы, которые кодируют и
расшифровать коды Рида-Соломона. Эти ИС, как правило, поддерживают определенное количество
программируемость (например, RS(255,k), где t = от 1 до 16 символов). Недавний
Тенденция к дизайну VHDL или Verilog ( логических ядер или интеллектуальных
ядра свойств ). Они имеют ряд преимуществ по сравнению со стандартными ИС.
Логическое ядро может быть интегрировано с другими компонентами VHDL или Verilog. синтезируется в FPGA (программируемая пользователем вентильная матрица) или ASIC (приложение
Специальная интегральная схема) это позволяет использовать так называемую «систему на кристалле».
конструкции, в которых несколько модулей могут быть объединены в одну ИС. В зависимости
на объемах производства логические ядра часто могут давать значительно более низкие системные
дороже, чем «стандартные» ИС. Используя логические ядра, разработчик избегает
потенциальная необходимость сделать «пожизненную покупку» микросхемы Рида-Соломона.
Внедрение программного обеспечения
До недавнего времени программные реализации в «реальном времени» требовали
слишком большая вычислительная мощность для всех, кроме простейших кодов Рида-Соломона
(т.е. коды с малыми значениями t). Основная трудность в реализации
Коды Рида-Соломона в программном обеспечении заключаются в том, что процессоры общего назначения не
поддерживают арифметические операции с полем Галуа. Например, для реализации
Умножение поля Галуа в программном обеспечении требует теста на 0, две логарифмические таблицы
поиск, добавление по модулю и просмотр таблицы анти-журнала. Однако тщательный дизайн
вместе с повышением производительности процессора означают, что программные реализации
могут работать на относительно высоких скоростях передачи данных. В следующей таблице приведены некоторые
пример результатов тестов на ПК с процессором Pentium 166 МГц:
| Код | Скорость передачи данных |
| RS(255,251) | 12 Мбит/с |
| RS(255,239) | 2,7 Мбит/с |
| RS(255,223) | 1,1 Мбит/с |
Эти скорости передачи данных предназначены только для декодирования: кодирование значительно быстрее, поскольку требует меньше вычислений.
5. Дополнительная литература
В этой статье мы намеренно избегаем обсуждения теории и
Подробная реализация кодов Рида-Соломона. Для получения более подробной информации, пожалуйста
см. следующие книги:
1. Викер, «Системы контроля ошибок для цифровой связи и Хранение», Prentice-Hall 1995
2. Лин и Костелло, «Кодирование с контролем ошибок: основы и приложения», Прентис-Холл 1983
3. Кларк и Кейн, «Кодирование с исправлением ошибок для цифровых коммуникаций», Пленум 1988
4. Уилсон, «Цифровая модуляция и кодирование», Прентис-Холл. 1996
6. Об авторах
Этот документ был написан Мартином Райли и Иэном Ричардсоном. Для получения более подробной информации об авторах нажмите здесь.
Copyright 4i2i Communications Ltd 1996, 1997, 1998
кодирование.Чтобы работать с этими данными, я попытался узнать больше о Рид-Соломоне и я обнаружил, что почти все объяснения мне бесполезны — куча продвинутых математике, но нет руководства по использованию R-S на практике. А на самом деле довольно много оказалось, что на страницах, перегруженных математикой, неправильные практические детали.
Математика Рида-Соломона действительно очень красивая, и я могу понять, почему многие объяснения начинаются с рассказа пользователям о прекрасных полях Галуа. Этот тем временем страница будет посвящена вещам, которые вам действительно нужно знать.
Эта статья не сделает вас экспертом по Риду-Соломону. Это будет однако позволяет вам понимать и использовать любые коды RS, которые вам нужны для работы с. Кроме того, вы узнаете, что может и чего не может R-S, и как это относится к другим системам исправления ошибок. Наконец, с этим понимание, тем больше математических объяснений может стать больше доступный.
Я хотел бы поблагодарить Фила Карна, KA9Q, за указание на меня к различным интересным документам и прояснению некоторых недоразумений, которые я имел.
Короче говоря, Reed-Solomon — отличный способ защитить сообщения от повреждения или частичное прибытие. По вашему выбору вы можете добавить t символов четности в сообщение.
Эти t символы четности позволяют:
Символ может иметь длину 8 бит и равняться байту, но это не обязательно.
Мало того, что это довольно хорошая устойчивость к ошибкам, лучше, чем это (в по крайней мере, не на символьной основе). 9с-1\), где \( с\) размер символа в битах.
Обратите внимание, что для 7-битных символов размер блока составит 127 символов или 889 символов. всего бит, что эквивалентно примерно 111 байтам.
Чем больше символов четности вы добавляете, тем меньше места остается для вашего сообщения в блок.
(255 223)
Очень распространенная конфигурация R-S обычно описывается как «(255 223)». Это означает, что размер блока N равен 255, что означает, что размер символа 8 бит. Второе число означает, что 223 ( K ) этих символов являются полезной нагрузкой, а 255-223 = 32 ( t ) байтов являются символами четности.
Эта конфигурация может восстановить 16 поврежденных байтов в любом месте 255 блок размером в байт. Эти искажения могут быть в самом сообщении или в символы четности, разницы в воздействии нет.
В качестве дополнительного свойства, если вы можете сообщить декодеру, какие символы поврежден, вы можете восстановить 32 «стирания».
Если имеется от 16 до 32 искажений в неизвестных местах, R-S будет в хотя бы рассказать о них. Если больше данных повреждено, сообщение может снова стать «действительным».
Это означает, что операция R-S может привести к следующим результатам:
- Сообщение получено правильно
- Сообщение было восстановлено из-за ошибок/отсутствующих данных
- Сообщение было правильно распознано как поврежденное, восстановить его не удалось
- Было повреждено так много битов, что мы случайно приняли сообщение как правильно/восстановлено
Поскольку невозможно отличить исход 4 от исходов 1 и 2, R-S не заменяет функции криптографической целостности!
Параметры
Обычно говорят о «(255,223)» Рида-Соломона, но это описание ужасно неполный. Имейте в виду, что если вы получили (255 223) спецификацию, это недостаточно для взаимодействия. Или, другими словами, вам нужно знать больше.
Вот полный набор параметров, необходимых для указания Конфигурация Рида-Соломона:
- Размер символа в битах (часто 8)
- Количество символов четности ( t или «количество корней»)
- (Подкладка, о которой позже)
- Коэффициенты полинома расширенного генератора поля Галуа
- Примитивный элемент в поле Галуа, используемый для генерации полинома генератора кода Рида-Соломона
- Первый последовательный корень многочлена генератора кода Рида-Соломона
Первые три элемента могут быть получены из «(255,223)», однако остальные осталось подобрать. 98\)
В качестве «примитивного элемента» вы можете выбрать любое число до 255, если оно не делится ни на 3, ни на 5, ни на 17. Это связано с тонкостями поле Галуа, используемое в 8-битном R-S. На практике люди часто выбирают 11, но вы также можете использовать, например, 7, 8, 13, 14, 16 или 19. я сделал кое-что при тестировании оказалось, что 8, 11 или 14 — одни из самых быстрых.
Для «первого последовательного корня», насколько я могу судить, можно выбрать любой меньше 255. Почему-то люди иногда выбирают 121, а я нет. знаю, почему. Возможно, потому что это то, что сделал «Вояджер»? Кажется, нет влияние на производительность в любом случае.
Таким образом, есть довольно много параметров, которые вы должны выбрать, но пока вы выберите одно из значений, предложенных выше, вы должны быть хорошими.
Некоторые примеры
Чтобы понять, как это работает, я написал небольшой инструмент, основанный на отличном библиотека fec Фила Карна, КА9Q и Роберт Х. Морелос-Сарагоса. Вы можете скачать предварительно скомпилированный бинарный файл Linux здесь, или получить источник от Гитхаб.
Обратите внимание, что этот инструмент автоматически дополняет ваше сообщение, чтобы оно имело правильную длину, и скрывает это от вас в выводе.
Четность выдается по основанию 16.
Все эти настройки можно менять по желанию (см.
--help). Теперь давайте посмотрим если декодирование работает. Обратите внимание, что сообщение было повреждено:$ ./rscmd --nroots 8 «Это поддельное сообщение» 7642b8e385fcf392 Исправлено 4 ошибки в позициях: 10 11 12 13 Восстановлено: это тестовое сообщение.Здесь мы испортили 4 байта, это столько, сколько можно исправить с помощью 8 байты четности. И это сработало! Если мы испортим еще одну позицию, Рид-Соломон гарантированно обнаружит это, всего до 8 повреждений:
$ ./rscmd --nroots 8 "xHIS является ложным сообщением" 7642b8e385fcf392 Фатальная ошибка: Не удалось исправить сообщениеОднако Рид-Соломон может исправить все 8 искажений, если мы скажем декодеру где они находятся:
$ ./rscmd --nroots 8 "xHIS является поддельным сообщением" -e 0 -e 1 -e 2 -e 3 -e 10 -e 11 -e 12 -e 13 7642b8e385fcf392 Информирование декодера о 8 стираниях: 0 1 2 3 10 11 12 13 Исправлено 8 искажений в позициях: 0 1 2 3 10 11 12 13 Восстановлено: это тестовое сообщение.Наконец, обратите внимание, что вы также можете повредить байты четности, это все еще работает:
# vv vvvv $ ./rscmd --nroots 8 "Это тестовое сообщение" 7642b8e385fc0000 Исправлено 4 ошибки в позициях: 5 6 253 254 Восстановлено: это тестовое сообщение.
rscmdпозволяет настроить все параметры Рида-Соломона, включая образующий полином.Использование Рида-Соломона на практике
Как уже отмечалось, пока мы работаем с 8-битными символами, общее кодовое слово всегда будет иметь длину 255 байт.
В зависимости от ваших потребностей вам может понадобиться больше или меньше защиты. Обратите внимание однако это компьютерное оборудование лишь изредка искажает отдельные байты (как только они попали в ваш язык программирования, то есть). Гораздо чаще встречается у вас исчезает весь сектор, диск или банк памяти.
Однако вполне возможно, что ваша оперативная память искажает отдельные биты данных. Кроме того, контрольные суммы TCP и Ethernet достаточно слабые, чтобы проскользнуть незамеченным.
Однако это настолько редкое явление, что вам лучше положиться на криптографию, чтобы обнаруживать такие проблемы с целостностью данных и полностью повторять передачу. Р-С нет стоит в этом домене.
За, возможно, заметным исключением ZFS, которая в своем первоначальном внедрение обнаружило кучу повреждений, происходящих на серверах и дисках.
Одна из причин, по которой вы не видите большого количества поврежденных байтов, заключается в том, что и методы хранения внутри уже используют R-S или R-S-подобные алгоритмы, без того, чтобы это было раскрыто вам.
Гораздо более распространенной проблемой для программистов является полное исчезновение данные. Это происходит постоянно — часто выходят из строя диски, даже SSD, возможно. тем более даже. Кроме того, сети постоянно отбрасывают пакеты.
Erasure coding
В качестве примера предположим, что у нас есть аудиопоток, который мы хотим защитить от сбросил пакеты. Допустим, мы хотим добавить защиту от 20% пакетов потеря.
Для этого мы могли бы взять 4 исходных пакета, добавить к каждому из них 25% четности и размазать 4 оригинальных пакета поверх 5 новых, вот так:
Обратите внимание, что мы также должны добавить порядковый номер к каждому пакету. Это позволяет приемник, чтобы точно определить, какие пакеты отсутствуют.
Если ничего не потеряно, получатель ждет, пока не будут получены все 5 пакетов, и отменяет размазывание. В этом случае запуск декодера Рида-Соломона обнаруживать только любые (очень редкие) отдельные поврежденные байты.
Но если четвертый пакет потерялся, все будет выглядеть так:
Каждый из 4 исходных пакетов теперь имеет 25% дыру! Чтобы оправиться от что декодер R-S должен точно знать, какие части сообщения были получены потерянный. И, к счастью, мы это знаем, потому что знаем схему распределения и мы знаем, какой пакет был потерян.
Получив такую информацию, R-S может полностью восстановить четыре исходных пакета, и наш звуковой поток не прерывается.
Выше приведен очень простой пример того, как использовать R-S для повышения устойчивости. от серьезной потери данных. Обратите внимание, однако, что стоит поставить много мыслей в таких схемах. Как будет выглядеть потеря пакетов? Мощь это приходит в очередях? И какая задержка приемлема? Очень эффективный установка вполне может буферизовать 30 секунд данных, что бесполезно для живых интервью например.
Описанная выше схема также работает для избыточного хранения файлов и данных. Например, многие варианты RAID6 используют R-S более или менее так, как описано выше.
Несколько слов о заполнении
255 байт могут быть слишком большими для вашего сообщения. Один из способов справиться с это чтобы договориться о «дополнении». Как обычно реализуется, если вы «дополните» 100 байтов, это означает, что первые 100 байтов 255 кодового блока считаются равны нулю и не передаются.
Это превращает код (255 223) в (155 123). Использование отступов может сэкономить много полоса пропускания, не «тратя впустую» четность.
Заманчиво проявить хитрость и передать поле длины, чтобы вы может сделать кодовое слово с динамическим размером. Если вы это сделаете, поймите, что вам также придется отдельно добавьте R-S в поле длины, чтобы сделать это безопасным! В противном случае искажение в поле длины может выбить вас из колеи.
В качестве примера заполнения на странице GitHub упоминается выше вы можете найти небольшой инструмент называется
ipпротекткоторый использует сильно дополненный 8-битный код (N,K) = (6,4) для добавления двух дополнительных октетов к IP-адресу, чтобы обеспечить 2 символа защиты R-S.Некоторые мелочи
Как отмечено в Теории и практике контроля ошибок коды, Рид-Соломон действительно «идеален», но только в том случае, если ваша проблема четко укладывается в что R-S может сделать. Размер блока R-S является жестким параметром, и он может не учитываться.
Кроме того, в то время как R-S может фиксировать и обнаруживать повреждения в максимальном теоретическом количество символов, возможно, вы думаете не о символах, а о большем количестве символов. с точки зрения количества переворотов битов.
Если x битов перевернуты в вашем сообщении, это полностью испортит х символов. Другие коды исправления ошибок могут лучше справляться с такими проблемами. распределенный урон. R-S отлично справляется с исправлением пакетов ошибочных данных.
За последние несколько десятилетий многое стало известно об исправлении ошибок. коды. Современные протоколы связи используют такие вещи, как Turbo код, четность низкой плотности проверить код или еще более модный Polar код. Эти алгоритмы решают проблему «мягкого кодирования решений», которая подходит для работы с данными, отправленными по зашумленному каналу, где мы имеем дело не только с «единицами и нулями», но и с вероятностями значений, равных 1 или 0 (или многие другие значения).
Код Рида-Соломона подходит для кодирования с жесткими решениями, когда каждый символ имеет ясное значение. Тем не менее, R-S часто играет роль конкатенированного (или вложенный) код вместе с декодером мягких решений.
Хотя с кодами LDPC и Polar происходят очень умные вещи, эти не играют никакой роли в защите данных, которые не состоят из вероятности.
Суммирование
- Рид-Соломон в обычном 8-битном режиме работает с блоками по 255 байт
- Вы можете выбрать, какая часть такого блока будет иметь четность
- Если вы выберете t байта, ваша полезная нагрузка составит 255- t байта
- Затем декодер может исправить t/2 ошибок в неизвестных местах
- Также может исправлять t ошибки в известных местах (стирания)
- R-S также надежно обнаружит, но не исправит до t ошибок
- Для небольших полезных нагрузок можно «дополнить» некоторые или даже большую часть этих 255- t байтов полезной нагрузки
- R-S не заменяет проверки криптографической целостности!
- При использовании Reed-Solomon точно помните, как он настроен, (255 223) не говорит вам достаточно
- R-S обычно не требуется для защиты данных на диске или во время Передача по IP-сети против ошибок отдельных байтов
Однако- R-S может очень хорошо добавлять избыточность против выпавших дисков.
- Несмотря на то, что в кодах, связанных с вероятностями, много нововведений, Коды LDPC, Turbo и Polar не применимы для исправления ошибок. на конкретные биты и байты
Дополнительная литература
Во всех моих поисках я в основном находил запутанную информацию или описания, которые работает очень хорошо, если вы уже поняли Рида-Соломона.
Вот некоторые документы, которые мне пригодились:
- Знакомство с Ридом-Соломоном
- наполовину визуальное, наполовину математическое введение. Очень хороший.
- Коды Рида-Соломона — Томмазо Мартини
- Введение в коды Рида-Соломона: принципы, архитектура и реализация
- Кодирование и декодирование Рида-Соломона. Визуальное представление — Леон ван де Паверт
- Коды Рида-Соломона и исследование Солнечной системы Роберт Дж. МакЭлис и Лайф Суонсон
- Оптимизация кодов Коши Рида-Соломона для отказоустойчивых приложений сетевого хранения
- Арифметика конечного поля и кодирование Рида-Соломона и коды QArt (весело!) Расса Кокса
Из отзывов и моего личного опыта также видно, что Теория и практика контроля ошибок коды (Р.
 Теория и практика кодов, контролирующих ошибки. Перевод с англ.: И.И. Грушко, В.М. Блиновский. Под редакцией: К.Ш. Зигангирова — М.: Мир, 1986. — 576 с.
Теория и практика кодов, контролирующих ошибки. Перевод с англ.: И.И. Грушко, В.М. Блиновский. Под редакцией: К.Ш. Зигангирова — М.: Мир, 1986. — 576 с.
 е.
ошибки размером до 16 байтов в любом месте кодового слова могут быть автоматически
исправленный.
е.
ошибки размером до 16 байтов в любом месте кодового слова могут быть автоматически
исправленный.